
مقدمة
في هذا المقال سوف نتناول بعض العمليات التي تتم داخل ال Execution Plan في الاستعلامات على جدول واحد بدون Joins مع ملاحظة ان هذا المقال يعتمد على فهم القاريء لل SQL Server Indexes وكذلك فهم طريقة قراءة ال Execution Plan وكل ذلك تم تغطيته في المقالات السابقة.
ملاحظة جميع الامثلة تعمل على قاعدة بيانات AdventureWorks
Index Scan
في هذه العملية يتم تحميل كافة البيانات في ال Index و استخراج نتيجة الاستعلام منها و غالبا ما يختار ال optimizer هذه العملية للاسباب التالية
- ان يكون الاستعلام بدون Where
- ان يكون حجم البيانات المستخرجة كبير فيقرر ال Optimizer ان عملية بتحميل ال Index اقل تكلفة ن البحث بداخله
- ان تكون ال Statistics غير محدثة
Index Seek
هذه العملية مختلفة تماما عن ال Index Scan حيث هنا يتم البحث داخل ال Index و استخراج النتائج دون تحميله بكامله وهذه تعتبر اسرع طريقة لايجاد البيانات
في داخل ال Execution Plan ستجد ان عمليات ال Scan و ال Seek تتمثل بالعمليات التالية
- Clustered Index Scan
- Clustered Index Seek
- Non-Clustered Index Scan
- Non-Clustered Index Seek
كما هو ملاحظ تختلف على حسب نوع ال Index
Clustered Index Scan
SELECT *FROM Person.ContactType
في جملة الاستعلام السابقة لا يوجد استخدام ل Where اذا نريد استرجاع البيانات بالكامل و لذلك يختار ال Optimizer عملية Clustered Index Scan وتكون ال Execution Plan بالشكل التالي
 |
| شكل 01 - Clustered Index Scan |
و نلاحظ من ال ToolTip التالية عند الوقوف بالمؤشر فوق ال Clustered Index Scan

ان ال Estimated Number of Rows التي قام بحسابها ال Optimizer هي اجمالي عدد السجلات داخل الجدول ولذلك قام باختيار عملية Scan
كما نلاحظ ايضا في الجزء الخاص ب Output List يعرض اسماء العواميد الناتجة من هذه العملية وفي هذه الحالة كل العماويد في الجدول
Clustered Index Seek
واذا قمنا بتعديل الاستعلام باضافة Where للعمود الذي يحمل ال Clustered Index بالاستعلام التالي
SELECT *FROM Person.ContactTypeWHERE ContactTypeID = 5
ستنتج ال Execution Plan التالية
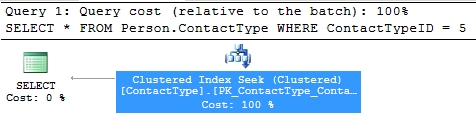
ونلاحظ انه تم اختيار Clustered Index Seek وهذا يعتبر امر ايجابي وبالنظر الى ال ToolTip الخاصة بهذه العملية

ستجد ان عدد السجلات المتوقع استخراجها رقم بسيط
و ايضا ستجد Section جديد باسم Seek Predicates وهو يوضح الParameter الذي تم استخدامه لعمل عملية ال Seek مع ملاحظة اننا كنا قد كتبنا الParameter عبارة عن رقم ثابت "5" ولكنه قام بتحويله لParameter و اعطى له اسم @1
Non-Clustered Index Seek
كما ذكرنا في المقال السابق ان الاختلاف الرئيسي بين ال Clustered و ال Non-Clustered Index ان
الClustered يحمل كل البيانات الفعلية في ال Leaf Level
بينما ال Non-Clustered يحمل بيانات العماويد التي تم عمل ال Non-Clustered Index عليها و العماويد التي تم عمل Include لها داخل ال Index اما باقي باقي بيانات العماويد الاخرى يحمل لها مؤشر في ال Leaf Level لمكان وجودها الفعلي في ال Clustered Index ويكون المؤشر عبارة عن ال Clustered Index Key.
انظر الاستعلام التالي
SELECT ProductID ,NameFROM Production.ProductWHERE Name = 'Blade'
الاستعلام يقوم بفلترة البيانات باسم المنتج و جلب فقط الاسم و ال ID
ويوجد بهذا الجدول Index باسم AK_Product_Name وهذا ال Index يعمل على عمود ال Name ولاننا قمنا بجلب ال Name و ال ProductID (الذي هوClustered Index Key) لذلك يتم جلب كل البيانات من ال Index دون الحاجة لعمليات اضافية كما بالشكل التالي

وعند النظر الى ال ToolTip كما بالشكل التالي نجد ان مخرجات العملية هي العماويد التي تم جلبها بالاستعلام

لكن ماذا يحدث اذا قمنا باضافة عماويد اخرى بال Select ليست متواجدة داخل ال Index الذي نقوم بال Where عليه
هنا ستظهر عملية اضافية لجلب بيانات هذة العماويد من ال Clustered Index انظر الاستعلام التالي
SELECT ProductID ,Name,ProductNumber,ListPriceFROM Production.ProductWHERE Name = 'Blade'
في هذا الاستعلام قمنا باضفة العماويد ProductNumber , ListPrice في ال Select نتج عن ذلك ال Execution Plan التالية

فنجد انه قام ال Engine بعمل Seek على ال Index باسم AK_Product_Name للبحث بداخله ثم قام بارجاع ال Name و ProductID و لجلب باقي البيانات قام بعمل عملية جديدة باسم Key Lookup بمعنى البحث بـKey على ال Clustered Index في هذا الجدول لجلب باقي البيانات و هي ProductNumber و List Price
اذا الوضع بعد عملية ال Key Lookup كالتالي
معنا قائمة بها Name و ProductID
معنا قائمة اخرى بها ProductNumber و List Price
لذلك قام ال Engine بعملية اخرى تسمى Nested Loops لربط القائمتين ببعض واظهار النتائج في قائمة واحدة عن طريق ربطهم بال ProductID وفي مقال تالي سوف نركز على ال Nested Loop بشكل اكثر تفصيلا.
ولتتبع ما يجري يمكن النظر الى ال ToolTip الخاصة بكل عملية وقراءة ال Output List بالاشكال التالية
 |
| Index Seek |
 |
| Key Lookup |
 |
| Nested Loop |
مما سبق يتضح انه في بعض الاحيان تكون هناك عمليات اضافية لجلب بيانات لا توجد داخل ال Non-Clustered Index ويمكن تجنب هذه الخطوات الاضافية بعمل Include لهذه البيانات داخل ال Index ولكن لا شيء بدون ثمن فكل مرة يتم تعديل هذه البينات يتم تعديلها داخل ال Index ايضا مما يؤدي الى اضافة جهد اضافي داخل عمليات الاضافة و الحذف و التعديل.
-------------------------------
مقالات سابقة
- مقدمة عن خطوات تنفيذ ال Query داخل ال Sql Server ؟
- نظرة بتعمق في ال Sql Server Execution Plan cache
- مقدمة عن ال Execution Plan
- SQL Server Index
مراجع
تم بحمد الله :)



ليست هناك تعليقات:
إرسال تعليق